Post-Training & Alignment — Overview¶
When I first trained this transformer from scratch, it could continue text but it couldn't
follow instructions or reason. That's what post-training fixes. This docs/ folder walks
through the whole journey I built on top of the base model — every stage written from scratch
in plain PyTorch (no trl, no peft, no transformers), trained on real public datasets, and
runnable on a single GPU or scaled across multiple GPUs with DDP.
If you are new to LLM training internals, start with the new LLM Foundations section before reading the stage pages. It explains the token shapes, decoder-only Transformer, attention masks, objectives, optimization loop, and generation mechanics that every later page relies on.
Recommended reading order¶
- Foundations first: Tokenization -> Transformer -> Attention -> Objectives -> Optimization -> Generation.
- Then the full pipeline: Data -> Pretraining -> SFT -> Reward Model -> DPO -> PPO -> GRPO.
- Finally run and inspect: Evaluation, Inference / Chat, and the command cheatsheet.
The pipeline mirrors how modern aligned/reasoning models are actually built:
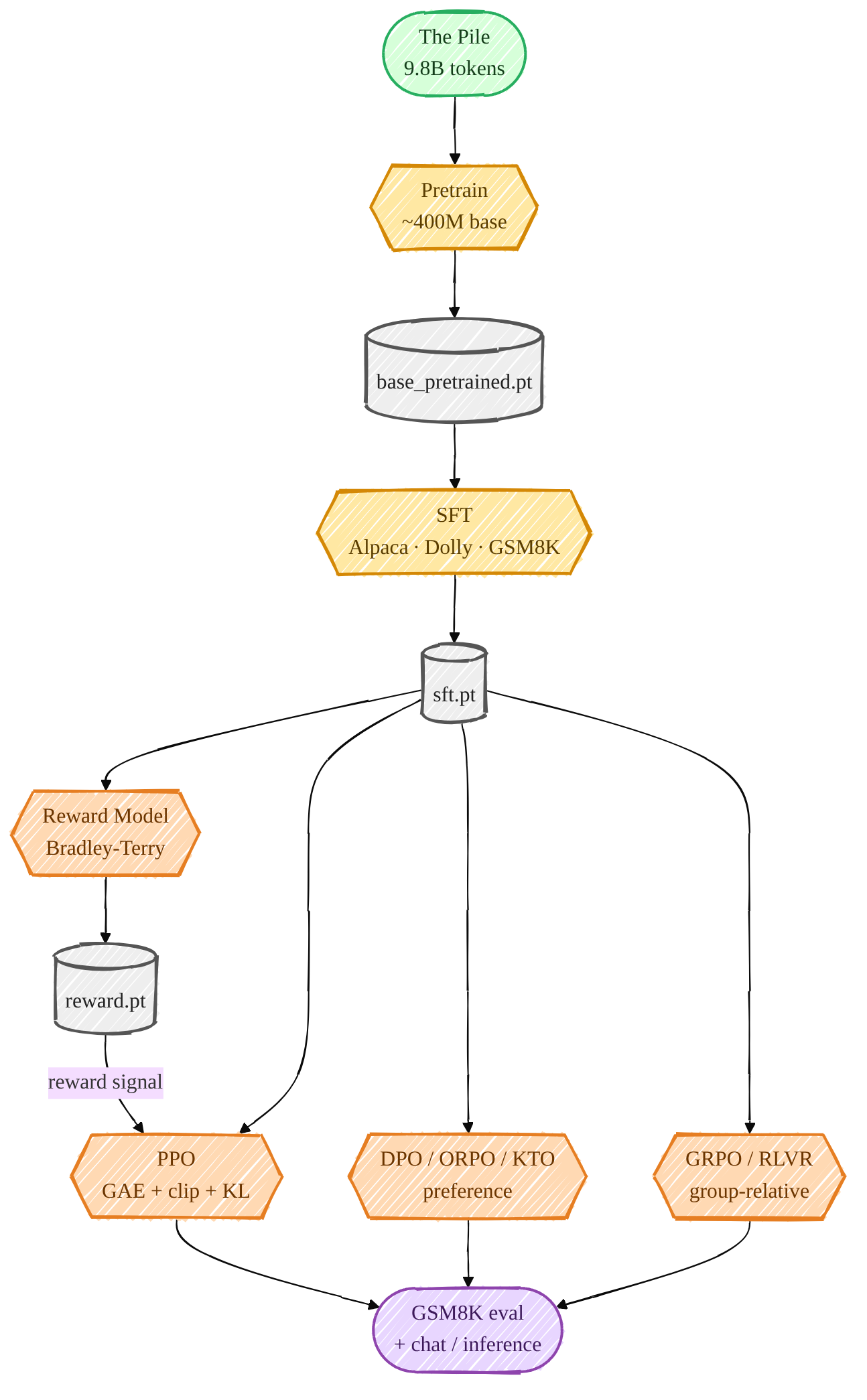
Mermaid source (live, editable)
flowchart TD
PILE([The Pile<br/>9.8B tokens]):::data --> PRE{{Pretrain<br/>~400M base}}:::model
PRE --> BASE[(base_pretrained.pt)]:::ckpt
BASE --> SFT{{SFT<br/>Alpaca · Dolly · GSM8K}}:::model
SFT --> SFTCK[(sft.pt)]:::ckpt
SFTCK --> RM{{Reward Model<br/>Bradley-Terry}}:::rl
SFTCK --> DPO{{DPO / ORPO / KTO<br/>preference}}:::rl
RM --> RMCK[(reward.pt)]:::ckpt
RMCK -->|reward signal| PPO{{PPO<br/>GAE + clip + KL}}:::rl
SFTCK --> PPO
SFTCK --> GRPO{{GRPO / RLVR<br/>group-relative}}:::rl
PPO --> EVAL([GSM8K eval<br/>+ chat / inference]):::eval
DPO --> EVAL
GRPO --> EVAL
classDef data fill:#d6ffd9,stroke:#27ae60,stroke-width:2px,color:#143d1a;
classDef model fill:#ffe8a3,stroke:#d48806,stroke-width:2px,color:#5a3d00;
classDef rl fill:#ffd9b3,stroke:#e67e22,stroke-width:2px,color:#6b3500;
classDef ckpt fill:#eeeeee,stroke:#555555,stroke-width:2px,color:#222;
classDef eval fill:#e8d6ff,stroke:#8e44ad,stroke-width:2px,color:#3d1a5a;The stages, in order¶
| # | Stage | What it teaches the model | Doc |
|---|---|---|---|
| 1 | Pretraining | language itself (next-token prediction on the Pile) | 02_pretraining.md |
| 2 | SFT | to follow instructions & produce the <think>/<answer> format |
03_sft.md |
| 3 | Reward Model | to score which answer humans prefer | 04_reward_model.md |
| 4 | DPO / ORPO / KTO | to prefer better answers without an RL loop | 05_dpo.md |
| 5 | PPO | to maximize a reward (RM or verifier) with the classic RLHF loop | 06_ppo.md |
| 6 | GRPO / RLVR | to reason, using verifiable rewards (DeepSeek-R1 style) | 07_grpo.md |
| — | Data pipeline | how every dataset above is downloaded & preprocessed | 01_data_pipeline.md |
| — | Evaluation | how I measure GSM8K accuracy across all stages | 08_evaluation.md |
| — | Inference / chat | how to actually talk to any checkpoint | 09_inference.md |
The one design rule: wrap, don't rewrite¶
Everything here sits on top of the original Transformer. I changed the
educational model in exactly one place — I added a forward_hidden
method that returns the final hidden states the lm_head consumes. Every post-training head (a value
head for PPO, a scalar reward head for the reward model) and every RL log-prob computation composes
around that one method, so the from-scratch model you already understand stays intact.
Colour legend (used in every diagram in these docs)¶
🟩 data / corpus · 🟦 preprocessing · 🟦⬛ storage (HDF5 / JSONL) · 🟨 model / training loop · 🟧 RL / reward · 🟥 loss / objective · 🟪 evaluation · ⬜ checkpoint
Each diagram is a hand-drawn, colour-coded Mermaid sketch, pre-rendered to a PNG and embedded as an image (GitHub's live Mermaid doesn't reliably do
look: handDrawn, and some viewers — e.g. the VS Code preview — block SVGs, so an embedded PNG shows everywhere). The editable Mermaid source sits in a collapsible "Mermaid source" block under each image. To regenerate the images after editing, see diagrams/README.md.
Run the whole thing¶
Once the base model has pretrained (02_pretraining.md), the entire chain is one script:
See POST_TRAINING.md for the condensed command reference.